Introduction to Multi-Threaded, Multi-Core and Parallel Programming concepts
In this article I’m going to present a gentle and modernized introduction to multi-threaded and parallel programming. While there are no concrete examples in this overview, I’m going to cover the general concepts and terminology, as well as an overview of the tools available to you as a developer to leverage multi-threaded techniques in our modern era of programming.
What is multi-threaded programming?
Single-threaded programs execute one line of code at a time, then move onto the next line in sequential order (except for branches, function calls etc.). This is generally the default behaviour when you write code. Multi-threaded programs are executing from two or more locations in your program at the same time (or at least, with the illusion of running at the same time). For example, suppose you want to perform a long file download from the internet, but don’t want to keep the user waiting while this happens. Imagine how inconvenient it would be if we couldn’t browse other web pages while waiting for files to download! So, we create a new thread (in the browser program for example) to do the download. In the meantime, the main original thread keeps processing mouse clicks and keyboard input so you can continue using the browser. When the file download completes, the main thread is signaled so it knows about it and can notify the user visually, and the thread performing the download closes down.
How does it work in practice?
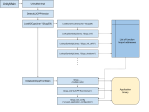
Most programs start off running in a single thread and it is up to the developer to decide when to spin up (create) and tear down (destroy) other threads. The general idea is:
- Application calls the system to request the creation of a new thread, along with the thread priority (how much processing time it is allowed to consume) and the starting point in the application that the thread should execute from (this is nearly always a function which you have defined in your application).
- Main application thread and secondary thread (plus any other created threads) run concurrently
- When the main thread’s work is done, or if at any point it needs to wait for the result of a secondary thread, it waits for the relevant thread(s) to finish. This is (misleadingly) called a join operation.
- Secondary threads finish their work and may optionally signal to the main thread that their work is done (either by setting a flag variable, or calling a function on the main thread)
- Secondary threads close down
- If the main thread was waiting on a join operation (see step 3), the termination of the secondary threads will cause the join to succeed and execution of the main thread will now resume
Why create threads?
There are a few main reasons:
- You need to perform a task which takes a long time to complete but don’t want to make the user wait for it to finish. This is called task parallelism and the threads which perform the long-running task are usually called worker threads. The purpose of creating the worker thread or threads is to ensure the application maintains responsiveness in the user interface, rather than to actually make the task run faster. Importantly, the task must be able to run largely independently of the main thread for this design pattern to be useful.
- You have a complex task which can gain a performance advantage by being split up into chunks. Here you create several worker threads, each dedicated to one piece of the task. When all the pieces have completed, the main thread aggregates the sub-results into a final result. This pattern is called the parallel aggregation pattern. See notes about multi-core processors below. For this to work, portions of the total result of the task or calculation must be able to be calculated independently – the second part of the result cannot rely on the first part etc.
- You want to serve possibly many users who need related but different tasks executing at the same time, but the occurrence time of these tasks is unpredictable. Classic examples are a web server serving many web pages to different users, or a database server servicing different queries. In this case, your application creates a set of threads when it starts and assigns tasks to them as and when they are needed. The reason for using a fixed set of threads is that creating threads is computationally expensive (time-consuming), so if you are serving many requests per second, it is better to avoid the overhead of creating threads every time a request comes in. This pattern is called thread pooling and the set of threads is called the thread pool.
There are numerous other use cases. I invite you to check out the section ‘Selecting the Right Pattern’ from the Microsoft Patterns & Practices page linked in the references below for more examples.
Threading on multi-core systems
If your processor has multiple cores, and your operating system supports it, creating a new thread will (or may by default) cause the new thread to be executed on an unused or least busy core. Therefore, running multi-threaded applications on multi-core systems is the primary way to take advantage of multiple cores and can enable a several-fold performance increase on complex tasks. If your application is multi-threaded, you can be mostly assured that it will automatically take advantage of multi-core processors. In contrast, on single-core processors, the threads will be time-sliced by the operating system in the same way processes are in a multi-tasking environment and all run on the single core, so there is no effective performance gain.
Note that there are laws of diminishing returns at work when using something like the parallel aggregation pattern: creating 4 worker threads will not necessarily lead to a 4-fold performance increase. Depending on the algorithms in use, the amount of co-ordination between threads, overhead from accessing memory shared between threads and other factors, the speed-up will be sub-linear. For more information see Amdahl’s law. Note also that algorithms which are well-designed for sequential (single thread/core) use are not necessarily optimized for multi-threaded/multi-core use and may need to be significantly re-designed.
Thread safety
Sometimes running several parts of your program at once can lead to unexpected behaviour or even cause memory corruption and crashes if you do not take precautions. If the same function can be executed in several threads simultaneously and independently without affecting each other, and additionally is designed to co-operate with other threads when accessing or changing their variables etc., the function is said to be thread safe.
Creating thread safe code is essentially the biggest problem and stumbling block for developers getting to grips with multi-threaded programming. Even experienced developers can come up across subtle and dangerous bugs which are very difficult to understand and debug. The most common issues are summarized below.
Race conditions
Imagine you have two functions running in separate threads, each writing their actions to a log (C++; we use the standard console output below but the principle is the same):
void myThread1()
{
while (true)
{
// do some work
// log it:
std::cout << "Hello World" << std::endl;
}
}
void myThread2()
{
while (true)
{
// do some work
// log it:
std::cout << "The quick brown fox" << std::endl;
}
The order of execution of the two threads, and when the threads get time-sliced and control passed to the other thread is unpredictable. This is acceptable and usually what you want, since the tasks are to run independently. You might expect an output like:
Hello World
Hello World
The quick brown fox
Hello World
The quick brown fox
The quick brown fox
The quick brown fox
Hello World
Hello World
or any other random combination of output of these two lines of text depending on how the threads are time-sliced. Unfortunately, things are not so simple. The thread may get time-sliced during the call to cout, and the other thread could output an entire line (or more) before the other thread’s call to cout is allowed to finish. This leads to weird output like this:
Hello WorThe quick brown fox
The quick brown fox
ld
This is almost certainly not what you want. Here the problem is quite harmless, but in real applications this can easily cause file or database corruption if two threads are writing to the same output (as they are above, writing to the console).
Race conditions are essentially when an operation which is meant to be atomic – that is to say, it should be completed as a single un-interruptable operation, not started at all, or rolled back to the previous state if completion failed – is indeed interrupted part-way through. In the example above, we incorrectly assume that writing to the console (or a log file) is an atomic operation, and we expect it to behave as an atomic operation, but in fact it does not.
A similar situation can arise with database tables, variables, or any other storage medium. Two threads updating the same rows in a database pseudo-simultaneously without protecting against a race condition may lead to the rows being partly updated with the data generated by one thread, and partly from the data by another (depending on the database architecture). Obviously this is a very dangerous result as the updated rows may be inconsistent.
There are various ways to solve this problem but the most common is by use of so-called synchronization objects. Details below.
Deadlock
Threads A and B both require access to two resources R1 and R2. These could be files, database tables, windows, printers etc. Each resource can only be acquired (owned and controlled) by one thread at a time, and the resources are acquired in a non-deterministic (unpredictable) order. Sometimes, thread A acquires R1 and is waiting to acquire R2, while thread B has acquired R2 and is waiting to acquire R1 – or vice versa. Each thread is waiting to acquire the resource owned by the other thread, causing an infinite wait loop. This situation is referred to as a deadlock.
There are various techniques to avoid, detect and prevent deadlocks (see the References section for a link to further information). Re-engineering the code so that both resources are acquired as a single atomic operation (eg. using a synchronization object – see below) can help, or you can introduce a time-out such that if only one of the two resources can be acquired in a fixed period of time, the acquired resource is released and the thread gives up or tries again later. One must be careful though, as such pre-emptive behaviour from both threads can lead to a race condition!
Synchronization objects
Synchronization objects allow threads to communicate with each other by signalling events of any kind; for example, indicating that a resource is being accessed and that other threads wanting to use the resource should wait to avoid the problems above. The most commonly used synchronization objects are critical sections, mutexes and semaphores.
Critical sections
Race conditions can be solved by the use of critical sections, which are designed to enable blocks of code to execute in a pseudo-atomic way (see below), and to ensure that only one thread at a time can read from or write to a specific resource.
A critical section is essentially an object shared between threads, but which can only be owned or acquired by one thread at a time. When one thread has acquired the critical section and another thread tries to do the same, the second thread must wait until the first thread has released it. Calls to enter (acquire) and leave (release) a critical section are wrapped around code which uses a particular shared resource. Therefore, the critical section can be seen as a kind of lock which prevents code ‘inside’ a particular critical section in one thread being executed at the same time as other code inside the same critical section in any other thread, ie. mutually exclusive execution of code inside the same critical section across multiple threads is guaranteed.
Whew, that was a mouthful. An example (using the standard Windows implementation of critical sections) should clear things up:
CRITICAL_SECTION critSection;
void myThread1()
{
while (true)
{
// do some work
// log it:
EnterCriticalSection(&critSection);
std::cout << "Hello World" << std::endl;
LeaveCriticalSection(&critSection);
}
}
void myThread2()
{
while (true)
{
// do some work
// log it:
EnterCriticalSection(&critSection);
std::cout << "The quick brown fox" << std::endl;
LeaveCriticalSection(&critSection);
}
int main()
{
InitializeCriticalSection(&critSection);
...
// make threads using myThread1 and myThread2 and wait for them to finish
...
DeleteCriticalSection(&critSection);
}
The critical section structure is set up when the program starts and torn down when it ends. The use of the shared resource (in this case, the console output) in each thread is wrapped inside the same critical section. The function call to enter the critical section tries to acquire ownership of critSection. Only one thread at a time can own it, so if another thread is currently using it, the requesting thread stalls until the critical section has been released in the owning thread (the thread currently using it), which occurs when that thread leaves the critical section. This mechanism therefore guarantees that only one thread at a time can execute code wrapped inside calls to enter or leave critSection.
The operating system ensures that the actual function calls to enter and leave critical sections themselves are executed atomically, so there is no risk of the thread being time-sliced while the critical section itself is being acquired or released, as this would leave critSection in an inconsistent state.
Note that although a thread can still be time-sliced while executing the code wrapped inside a critical section, the time-sliced thread will still own the critical section, so other threads waiting to acquire it will continue to wait until the owning thread re-gains control, finishes its work and releases it. Therefore, as long as all other threads using the same resources wrap these uses in the same critical section object, the operation of everything inside the critical section is guaranteed to be atomic (as far as other threads using the same resources are concerned).
If you’re still confused, you can consider acquiring a critical section to be akin to locking a non-shareable resource. A given critical section will usually be associated with code that accesses a particular resource. For example, our critSection above may have been better named something like cs_consoleAccess, to indicate that whenever we want to lock the console output for writing only by a single thread temporarily, we will do so by acquiring ownership of cs_consoleAccess. Then we know that any other thread which wants to write to the console output must also acquire cs_consoleAccess, and will be forced to wait until we have finished writing to it (and release the critical section) in our thread. This makes for more readable code.
Although I have used the Windows API above, the principles are the same for all platforms which support multi-threading. More details on APIs follow below.
Mutexes and semaphores
Mutex stands for mutually exclusive and is a structure which operates very similarly to a critical section. In Windows, the main difference is that a mutex can be given a name, and named mutexes can be shared across process boundaries as well as between threads. If you are writing applications which use more than one process, a named mutex can be used to prevent more than one process from accessing a given resource at the same time. Mutexes can also be used within a single process in the same way as critical sections, if desired.
Semaphores are like mutexes except they allow multiple acquisition (several threads can acquire the semaphore at once). A semaphore maintains a count of how many times it has been acquired, and prevents further acquisitions when a user-defined maximum is reached. This enables a certain maximum number of threads to use a resource simultaneously, but no more. This can be handy if you need to create a deliberate bottleneck or throttle to prevent a resource from being overloaded, or if it only supports a maximum number of connections and you don’t know in advance how many threads will be trying to access it.
Other synchronization objects and inter-thread communication
Critical sections, mutexes and semaphores are commonly used but there are other tools at your disposal. Waitable call timers allow a thread a certain amount of time to execute and either terminate it or send a signal elsewhere in your application if the thread fails to complete in the allocated time limit. Events can be used to signal occurrences in one thread to another thread. Still other lesser-used constructs are also available. The Synchronization link in the References section provides further information.
Deadlocks revisited
Injudicious use of critical sections, mutexes and semaphores can cause deadlocks. If you re-visit the explanation of deadlock above and substitute two shared critical sections for R1 and R2, you can easily see how this can happen. The biggest risk occurs when the attempt to acquire several critical sections (or other synchronization objects) is nested:
CRITICAL_SECTION databaseTable1;
CRITICAL_SECTION databaseTable2;
void myThread1()
{
EnterCriticalSection(&databaseTable1);
EnterCriticalSection(&databaseTable2); // nested - only runs once databaseTable1 is acquired
...
LeaveCriticalSection(&databaseTable2);
LeaveCriticalSection(&databaseTable1);
}
void myThread2()
{
EnterCriticalSection(&databaseTable2);
EnterCriticalSection(&databaseTable1); // nested - only runs once databaseTable2 is acquired
...
LeaveCriticalSection(&databaseTable1);
LeaveCriticalSection(&databaseTable2);
}
Without a time-out, or wrapping the acquisition of the two tables inside a third critical section, these threads could easily end up deadlocked as each acquires a table and then waits endlessly for the other thread to release the other table needed.
Creating a multi-threaded program – which library to use?
So far I have avoided giving concrete code examples, mainly because the code to do so is highly platform-dependent. Generally, you can use the built-in threading functions of your platform or programming language of choice, or a higher-level abstraction or library.
- On UNIX/Linux, the standard is the POSIX Threads library Pthreads (YoLinux tutorial).
- On Windows (low-level, eg. C/C++), the Windows Processes and Threads APIs are the default choice (MSDN Processes and Threads Reference).
- If you are using the .NET Framework, the System.Threading namespace provides an API (MSDN Managed Threading guide).
Some higher level libraries include:
- Boost.Thread is a C++ library which provides threading in a simplified and portable (multi-platform compatible) way
- OpenMP is an open-source multi-processing library with a rich and mature feature-set. It is also cross-platform compatible
- PPL is the new Parallel Patterns Library bundled with new versions of the C++ standard library in Visual Studio. A very similar version called PPLx for Linux is also available. PPL attempts to leverage new syntax and language constructs available in C++11 to make multi-threaded programming easier, mostly doing away with direct use of synchronization objects altogether. PPL is one of the APIs of the new Concurrency Runtime (ConcRT) for C++ (see link in References).
- C++11 includes a new set of features called futures and promises (conceptual overview on Wikipedia), as well as most of the stuff from Boost.Thread included in the C++ standard library. These provide multi-threading capabilities in C++ out of the box (Just Software Solutions futures, promises and asynchronous calls tutorial)
Coming next…
In lieu of proper examples on the internet, I shall in the next couple of articles demonstrate how to solve a common parallel aggregation problem – that of adding a large sequence of numbers – using two different libraries, either C++11 or Boost, and the so-far little-understood PPL.
I hope you found this overview useful. Please leave feedback below!
References
While I was researching this article I found another excellent introduction to multi-threading by Vivien Oddou which covers a number of additional issues to those mentioned here.
Other useful links:
Microsoft Patterns & Practices: Introduction to Parallel Programming
Overview of the Concurrency Runtime (Visual Studio 2012)
Deadlock overview on Wikipedia
Microsoft Dev Center: About Synchronization
Share your thoughts! Note: to post source code, enclose it in [code lang=...] [/code] tags. Valid values for 'lang' are cpp, csharp, xml, javascript, php etc. To post compiler errors or other text that is best read monospaced, use 'text' as the value for lang.
Katy would love it if you could help keep her stocked with cookies while she codes!





Thank you Katy for explaining the concepts very easily . Hope you feel better soon .
A superb re-introduction to concurrent programming Katy, updated as you wrote for modern multi-core processors. Your writing style is terrific too. Many thanks
very nice post, really enjoyed reading and got some nice informations too.
I am working on a complex calculation program in C++ so an introduction post like this is very helpful. thanks
nice and helpfull article